개요
LLM(대형 언어 모델)이 생성한 코드는 컴파일되고, 테스트를 통과하고, 올바르게 보이더라도 근본적으로 잘못되었을 수 있다는 것을 실제 사례를 통해 분석한 글.
핵심 벤치마크 결과
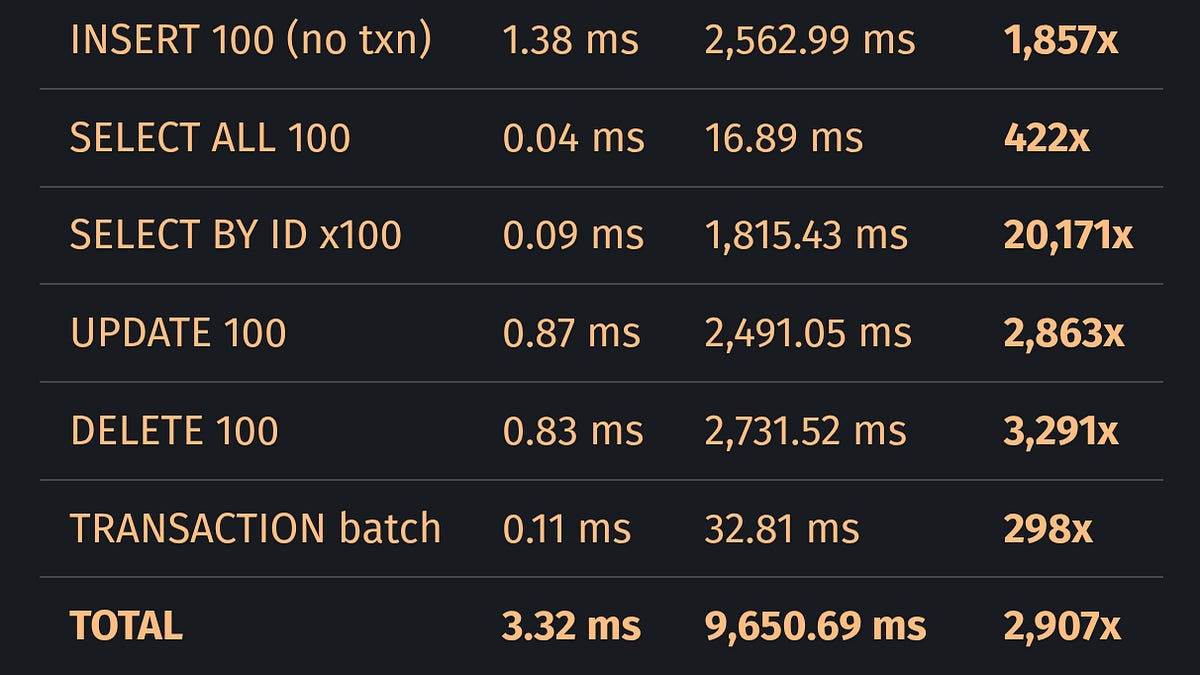
- SQLite (C 원본): 100개 행 기본키 조회 → 0.09ms
- LLM 생성 Rust 재구현: 동일 작업 → 1,815.43ms
- 성능 차이: 20,171배 느림
- 해당 Rust 프로젝트는 576,000줄 규모, MVCC 동시 쓰기, SQLite 파일 호환성, C API 드롭인 등을 README에서 주장함
- 코드는 컴파일되고, 모든 테스트 통과, 올바른 SQLite 파일 포맷 읽기/쓰기 가능 → 외형상 완전한 DB 엔진처럼 보임
발견된 주요 버그
버그 #1: INTEGER PRIMARY KEY 인식 실패 (ipk 체크 누락)
- SQLite에서
id INTEGER PRIMARY KEY는 내부 rowid의 별칭 →WHERE id = 5는 O(log n) B-트리 탐색으로 처리됨 - SQLite 원본의
where.c에서iColumn == pIdx->pTable->iPKey이면XN_ROWID로 변환 →SeekRowid실행 - Rust 재구현의
is_rowid_ref()함수는 단 세 가지 문자열만 인식:"rowid","_rowid_","oid"
id INTEGER PRIMARY KEY로 선언된 컬럼은 내부적으로is_ipk: true로 표시되어 있어도 인식되지 않음- 결과: 모든
WHERE id = N쿼리가 전체 테이블 풀스캔(codegen_select_full_scan())으로 처리됨 - 100개 행 × 100번 조회 = 10,000번 행 비교 (정상이라면 약 700번 B-트리 탐색)
- O(n²) vs O(n log n) → 20,000배 차이 설명됨
버그 #2: 매 명령문마다 fsync 호출
- 트랜잭션 외부의 모든 INSERT는 자동커밋 사이클을 거침 →
wal.sync()→fsync(2)호출 - 100번 INSERT = 100번 fsync → 1,857배 느림
- SQLite는 Linux에서 기본적으로
fdatasync(2)사용 (파일 메타데이터 동기화 생략) → 1.6~2.7배 빠름 - 배치 INSERT(트랜잭션 내): 32.81ms vs 개별 INSERT: 2,562.99ms → 78배 오버헤드
복합적인 성능 저하 요인들
각각은 "합리적인" 선택처럼 보이지만 합쳐지면 치명적:
1
검열관 메모 (3)
내용 요약 추가
코드를 신경안쓰면, 베지어 커브를 중복 구현한다던가..
성능을 똥망으로 만든다던가 하는 현상이 생기는것 같음. (지적하니 수정함)
음..